Hybrid Reward Architecture ( HRA ) impara a giocare a Pacman
Un algoritmo AI per generalizzare i problemi. Una start-up ha migliorato la tecnica di apprendimento con rinforzo ( reinforcement learning ) dell'intelligenza artificiale.
Si tratta di una nuova tecnica chiamata Hybrid Reward Architecture ( HRA ). Dai primi test sui problemi giocattolo, le scelte dell'algoritmo sono effettivamente migliorate.
Come funziona HRA
Nel reinforcement learning ( RL ) l'algoritmo individua le azioni migliori tramite una funzione obiettivo di riferimento da massimizzare.
Tuttavia, non tutte le situazioni reali sono semplificabili con un'unica funzione matematica. Purtroppo questo riduce le applicazioni possibili del modello RL.
Nell'architettura ibrida HRA la funzione ottimale è composta da più sottofunzioni. Ogni funzione massimizza un singolo aspetto.
Grazie a questa tecnica l'agente riesce a generalizzare meglio il problema da affrontare, anche un problema complesso, perché la funzione ottimale è l'insieme di più funzioni.
L'algoritmo decisionale è più flessibile e adattabile
Un esempio pratico
Un esempio di problema giocattolo non semplificabile è il vecchio videogame Ms. Pac-Man. Finora nessun programma AI aveva eguagliato le performance di un giocatore umano.
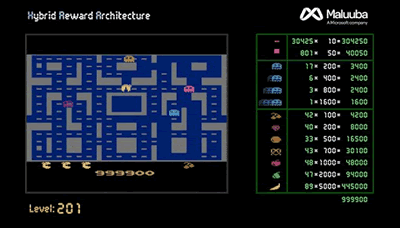
L'algoritmo HRA ha imparato da sé le strategie di gioco, ottenendo per la prima volta un punteggio più alto dei giocatori umani. Il che non è poco.
Mi sembra una soluzione interessante.
10/05/2018
Andrea Minini



